前一天我們簡略地介紹了CDF,Kraska et al. 發現對於排序好的Key值,其CDF的分布會近似於Key值的位置~
下面這張圖為Key 與 CDF 的曲線圖,取自The Case forLearned Index Structures.
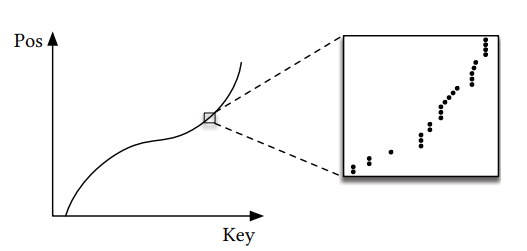
X軸為Key值,Y軸為Pos,這裡的Pos為經由CDF函式產生的近似位置,對於這樣的分布,Kraska et al. 提出使用Model學習CDF的分布,這也是整篇Paper的主軸,使用Model來訓練、學習資料的CDF分布,預測出資料的位置,那該講的都講完拉~~就這樣吧XD
開玩笑低..XD
Model的建置則是使用機器學習或是深度學習,可以是簡單的線性回歸(Linear Regression),也可以是多神經網路。
那可能會有人好奇,欸~所謂的學習CDF分布是怎麼學習? 通常建置模型不是要抓特徵,那特徵是什麼? 那標籤呢?
在這裡跟大家一一說明,特徵是Key值,標籤是CDF。
對...就是這樣XD,我們將所有Key值對應其CDF預測出的Pos拿去訓練,來建置模型。
最後只要輸入Key值經由Model就能吐出預測的Pos喔,真的牛逼阿 !
老話一句,一張圖勝過千言萬語 ~

Reference
Kraska, Tim, et al. "The case for learned index structures." Proceedings of the 2018 International Conference on Management of Data. 2018.

